
執筆:スティーブ・ザメック、ジョン・ホルト、サンディ・チェン
APEC 2026(セッション IS02.1:パワーデバイスのイノベーションを変革するAIとデジタルツイン)において、当チームは、パワー半導体メーカーとの10年以上にわたる経験から得られた、実稼働中のAI/ML活用事例を2件発表しました。本記事では、その主な教訓をまとめます。
このブログ記事とプレゼンテーションは、半導体およびパワー半導体製造におけるAI/MLの導入に関する実践的なアプローチについて、当チームが発表している一連の資料の一部です:
パワー半導体はなぜ特別なのか?
AIを活用した歩留まり向上については、ロジックやメモリの製造分野で多くの研究が行われてきた。しかし、パワー半導体(SiC、GaN、IGBT、ディスクリートシリコン)の製造環境は、独特な難しさを伴う。 使用される材料の種類が多く、欠陥率も高く、製造フローはより垂直統合が進んでいます。具体的には、インゴット成長、基板選別、エピタキシー、複数回のバーンイン工程、ダイアタッチ、モジュール組立などが挙げられます。また、製造設備は一般的に老朽化しており、成熟したシリコンファブが数年前にほぼ解決していたトレーサビリティやデータ品質の面でも、まだ成熟度が低いのが現状です。
Yoleの「2025年パワーエレクトロニクス産業レポート」で紹介された企業のうち11社が、Exensioのアクティブユーザーであり、いずれも10年以上利用しています。APECで発表した2つのユースケースは、これらの導入事例を通じて得られた知見を反映したものです。
ユースケース 1:SiCにおける基板による収率制限
問題点
SiC製造において、基板の品質は歩留まり低下の主な要因の一つです。問題は、どの基板が歩留まりを低下させるかを予測し、高額な後工程に進む前にその予測に基づいて対策を講じることができるか、ということです。
アプローチ
キラー欠陥を特定する従来の方法は、「キル・レシオ」という指標に基づいています。これは、2×2の交絡行列を用いて、「クリーン」なダイと「ダーティ」なダイの歩留まりを比較するものです。この方法は、各欠陥クラスごとのダイレベルの集計データに依存しています。シリコン基板自体はほぼ欠陥がないため、注目されるのは主に、ファブやファウンドリで発生したインライン欠陥です。
化合物半導体の場合、状況はより複雑です。複数の検査工程、ベア基板(エピタキシー前・後)、およびパターン形成済みウェーハ(インライン)を横断して作業を行うことになります。 ダイレベルの要約は、パターン化されていない基板上のダイグリッドが定義されていないため、適切に適用できません。また、電気的ウェーハソートのみに基づいてダイの良否を判断するだけでは不十分です。パワーデバイスには、独自の負荷条件下での大電流・高電圧試験が必要ですが、これらはウェーハソート中に実現できないことが多々あります。
当社のアプローチでは、素基板およびエピタキシャル欠陥のデータを用いて予測モデルを学習させ、電気的テストに先立ち、ダイごと、ウェーハごとの合格/不合格の予測結果を分類した「予測電気ビンマップ」を生成します。このモデルにより、オペレーターは基板を本格的な製造工程に投入する前に、そのグレードを判定することが可能になります。さらに、この予測はあらゆる仮想ダイサイズに対して実行できるため、ユーザーは異なるダイサイズを試行して歩留まりを推定することができます。
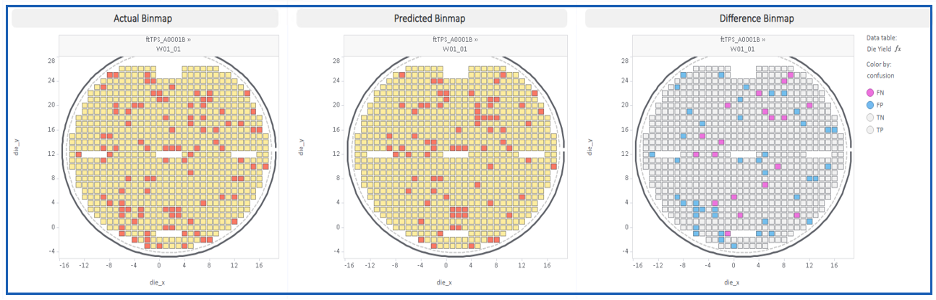
結果
以下で述べる結果は、複数の異なるサプライヤーから調達した炭化ケイ素(SiC)基板を用いた当社の経験に基づいています。とはいえ、このアプローチはSiCに限らず、他の種類の半導体にも適用可能です。量産環境においては、以下のモデルが適用されます:
- SiCの欠陥除去メカニズムに関する既発表の文献と整合し、収率を制限する基質を正確に特定する
- 上流工程での基板の選別判断を可能にすることで、歩留まりを数パーセントポイント向上させる
- 「実測値」「予測値」「差分」のビンマップを生成し、モデルの挙動を解釈可能かつ検証可能にする
また、このモデルは各欠陥クラスについて4つの分類カテゴリを提示しています:
- TP(真陽性):実際に合格、予測合格 — 判定は正しい
- TN(真陰性):実際の結果:不合格、予測結果:不合格 — 判定は正しい
- FP(偽陽性):実際には不合格だが、合格と予測される — 過小評価、歩留まりの低下要因
- FN(偽陰性):実際には合格だが、不合格と判定される — 過剰な措置であり、コスト面での負担となる
生産上の課題
パイロット段階から本番運用に移行する過程で、さまざまな課題が浮き彫りになった。
検査:同一の基板であっても、ロットや材料の流れが異なる場合、異なる検査装置で測定されることがあります。装置ごとに欠陥の分類基準が異なり、正規化を行わない限り、欠陥数を直接比較することはできません。また、検査レシピは未成熟であり、絶えず改訂されています。
空間位置合わせ:ベア基板に対する光学検査では、ウェーハ全体の座標系が使用されます。この座標系は、ダイ座標系に対して正確に位置合わせを行う必要があります。 多くの旧式のファブでは、ウェハ全体座標とダイ座標との間に適切な位置合わせが行われていない。さらに、非立方格子半導体(SiCなど)の欠陥は、サイズが大きく、複数のダイにまたがっている場合がある。しかし、検査スキャンでは、これらの欠陥の空間的な広がりを把握するのに十分な情報が得られない。
プローブおよびバーンイン:データの品質が低いという問題は常態化しています。方向の誤差、検査座標とテスト座標間のダイオフセット、ダイIDの表記規則の不統一などが原因で、空間的な位置合わせは容易ではありません。そのため、有意義なモデルを構築するには、事前にデータのクレンジングと検証を行う必要があります。
モジュール+バーンイン:多くのメーカーが、ダイのエンドツーエンドのトレーサビリティに苦慮しています。基板レベルでの選別や格付けが行われるため、エピタキシー後のファブロットは、エピタキシー前のロット構成とは全く異なるものになる可能性があります。ウェーハ選別を行うと、1つのロットに含まれるウェーハのほぼすべてが、異なるエピタキシー前の材料ロットに由来している可能性があります。モジュール組立段階では、サブアセンブリ間で個々のダイを追跡することになります。
欠損データ:さらなるバイアスのリスクをもたらします。検査データが欠落しているレコードを単に除外する場合、その除外はランダムに行われているわけではありません。 特定のツールタイプ、時間枠、または材料グレードの記録が除外されやすくなり、その結果、トレーニングセットに体系的なバイアスが生じます。例えば、欠損データは、組み立て工程で不良ダイスが選別されることに起因することがよくあります。これらのダイスを除外することは、多数の不良ダイスを除去することを意味し、その結果、過度に楽観的なモデル(いわゆる「アンダーキル」)が生成されることになります。
ユースケース 2:組立工程における予測ダイ・ビニング
問題点
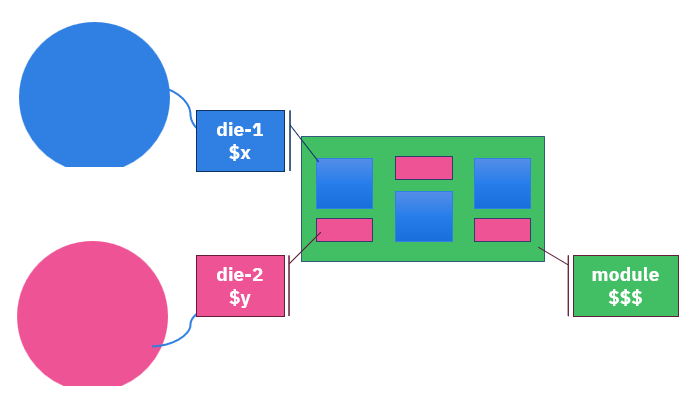
自動車用トラクションインバータなどのパワーモジュールは、複数のウェーハから供給された複数のダイを組み立てて製造される非常に高価な部品であり、多くの場合、複数の製品や複数のベンダーが関与しています。不良ダイがモジュールに組み込まれてしまうような品質管理の不備は、莫大なコストを招きます。そこで問題となるのは:ウェーハソートデータから最終テストの結果を予測し、その予測を用いて組み立て前のダイ配置を最適化することは可能か?
これはパワー半導体に限った話ではありません。ハイエンドのコンピューティングモジュール(データセンター向けMCM)も同様の課題に直面しています。どちらも1モジュールあたり数十個のダイを搭載しています。いずれの場合も、モジュールが故障した際のコストは、そのモジュール内のすべてのダイの組立コストに波及することになります。
アプローチ
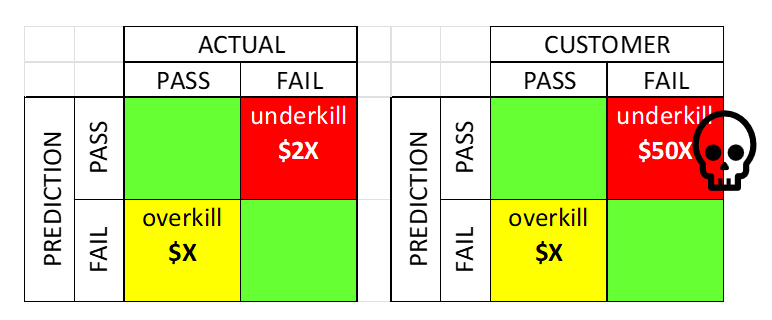
目標は、ウェハソート時のパラメトリックデータを用いて学習させた二値分類器(モジュール最終テストの合否判定)を構築し、精度ではなく最終的なモジュールコストを最適化するように分類閾値を調整することである。
なぜ精度ではなくコストなのか?それは、性能不足と性能過剰のコストに著しい非対称性があるからだ。モジュールテストに不合格となるダイをアセンブリ工程に送ると、モジュール全体の組み立てコストが無駄になり、その額は個々のダイのコストの50倍に達する可能性がある。一方、正常なダイに対して過剰な処理を行っても、無駄になるのはそのダイ自体のコスト(xドル)だけである。最適な分類器とは、こうした非対称的な結果を考慮した上で、総期待コストを最小化するものである。
現実世界の複雑さ
この種のソリューションの実環境への導入は非常に複雑です:
- データの不整合や欠落:製造工程における実際のビンマップやパラメトリックマップは、空間的に歪んでいたり、テストが不完全であったり、データ変換によって破損していたりする場合があります。これは、テスターとプローバーが異なるエンジニアリング部門によってプログラムされることに起因しています。プローバーの役割はウェハー上の正しいダイに正確に位置合わせすることですが、テスターはテストプログラムの実行に重点を置いているためです。 その結果、テスターの出力には、ダイサイズや座標、さらにはウェーハの向きが誤っていることが頻繁に発生します。
- 複数のテスト工程:ウェーハプローブ、ウェーハバーンイン、モジュール組立テスト、モジュールバーンイン、最終テスト。それぞれに独自のデータ形式、許容限界、およびビニング基準が存在します。これにより、いくつかの疑問が生じます。良品と不良品のダイの「真の基準」とは何でしょうか?テストでは良品と判定されたものの、インクアウト(インク塗布)されたため、空間的な外れ値スクリーニング(例:GDBN)によってその後のテストに進めなかったダイについては、どう扱うべきでしょうか?
- 数十個のダイを搭載したモジュール:製品、ロット、製造プロセスがそれぞれ異なり、それぞれに独自の予測モデルとトレーサビリティ要件が必要となります。数十個のダイを搭載したモジュールでは、モデルのトレーニング負荷が爆発的に増加します。このようなモデルのトレーニングには、多くのメーカーが導入できないほどの計算インフラが必要となります。
- 複数のサブアセンブリ:部品は段階的なサブアセンブリ工程を経ます。ある工程で組み立てられ、検査された部品は、より高い統合レベルでの次のサブアセンブリの材料となります。 ここで疑問が生じます。最適化の目標は何でしょうか?各サブアセンブリ工程では個別の判断(分類)が必要ですが、最終的な目標はすべてのサブアセンブリ工程の合計コストです。サブアセンブリ工程の数が増えるにつれて、その複雑さは飛躍的に増大します。
- トレーサビリティの低さ:パワー半導体の製造において、ウェハーからモジュールに至るまでのダイのトレーサビリティを確保するには、明確な技術的取り組みが必要であり、自動的に行われるものではない
当社の生産環境への導入においては、モデルのトレーニングを開始する前に、すべての製造業務にわたるデータの整合性を確保し、トレーサビリティを維持し、データセットが分析可能な状態になるよう、多大な努力を払っています。とはいえ、こうしたモデルの構築、検証、導入、および保守は依然として課題となっています。
データインフラの重要性
どちらのユースケースも、根本的な課題は同じです。それは、データを分析可能な状態にすることです。複数の顧客から、これらのモデルを本番環境で正常に運用するために必要なエンジニアリング作業の90%が、データの準備と検証に費やされているとの報告がありました。
パワー半導体業界における製造データは、実に断片化しています。ファブレス企業の場合、ダイは異なるベンダーから調達され、異なるOSAT(受託製造業者)に送られるため、そのすべてのデータを単一のプラットフォームに集約することは非常に困難な作業となります。自社で製造を行う垂直統合型のデバイスメーカーであれば、この作業はより容易だと考えられるかもしれません。 しかし、現実はそうではありません。データは同一企業の所有物であっても、複数の拠点やMES、ERP、QMS、FDC、SPCシステムなど多様なシステムに分散しており、拠点ごとに異なるシステムが使用されていることも珍しくありません。こうした各システムはサイロ化しており、そこでExensioのような歩留まり管理プラットフォームを全社的に導入することが極めて重要となります。
このような導入事例として、オンセミ(onsemi)を例に挙げてみましょう。2025年12月に開催されたPDF Solutionsユーザーカンファレンスにおいて、オンセミのトム・グレイン氏は、同社がExensioを単一のプラットフォームとして活用し、炭化ケイ素(SiC)粉末から結晶成長、エピタキシー、デバイス製造、モジュール組立に至るまでのSiC製造フロー全体において、唯一の信頼できる情報源としていることを紹介しました。 同社のデータ系譜チェーンは、ブール成長 → 基板 → エピタキシー → ファブウェーハ → モジュールという流れを追跡しています。このようなエンドツーエンドのデータインフラは、単なる「あれば便利なもの」ではありません。それは、本格的な分析を行うための必須条件なのです。
行動を促すメッセージ:データをAI対応にしましょう
パワー半導体メーカーにおける10年以上にわたる実稼働実績に基づき、AI戦略を成功させるための基盤を構築するために必要な要素は以下の通りです:
- 製造向けのITインフラを構築する。実用的な形で存在しないデータでは、AIモデルを実行することはできない。まずは、データの収集、保存、およびアクセスに関するインフラへの投資が最優先である。
- データのサイロ化を解消しましょう。製造データ、材料、製造ライン上のウェーハ、製造ライン上の装置、組立、およびテストに関するすべてのデータを、単一のプラットフォームに統合します。結合できないデータは、モデル化できないデータです。
- データは発生源でクリーンアップする。理想的には、データ品質は収集の段階で確保されるべきである 。それが不可能な場合は、データが分析環境に入る前に、フォーマットの標準化、値の検証、異常のフラグ付けを行う、企業全体の「データクレンジング層」を構築する。
- 拠点間および資材の流れ全体で標準化を図る。SEMI規格では、データ分析が抱える課題に対応できるほどの標準化は図られていない。メーカーは、各データ領域ごとに独自のデータ標準を策定し、拠点間および資材の流れ全体で一貫して適用する必要がある。
- サプライチェーンのトレーサビリティを確立する。パワー半導体では製品のバリエーションが豊富であるため、資材の流れも多様化しています。その流れは、完全自社生産、一部外注、完全外注(ターンキー)が混在する形となります。原材料から出荷済みモジュールに至るまで、出荷済みモジュールに含まれる特定のダイを、その原料まで遡って追跡することは容易なことではありません。しかし、パワー半導体の世界において、優れたモジュールと現場から返品されるモジュールの差を分けるのは、往々にして使用される材料なのです。
これら5つのステップは、製造の卓越性を実現するための前提条件です。不完全、整合性のない、あるいは偏ったデータで学習されたAIモデルは、誤った結果を生み出します。そして、生産処分システムにおいて、誤った結果は直接的なコスト面での影響をもたらします。
半導体業界におけるAIの変革は、すでに本格化しています。最大の価値を獲得するのは、必ずしも最も高度なモデルを持つメーカーではありません。それは、データが学習に適した状態になるよう、地味な作業を積み重ねてきたメーカーたちなのです。
この記事は、2026年3月24日にPDF Solutions社のスティーブ・ザメック氏、ジョン・ホルト氏、サンディ・チェン氏によって行われたAPEC 2026のプレゼンテーション「半導体のコストと品質を向上させる高度な分析とAI」(セッションIS02.1)に基づいています。