
作者:史蒂夫·扎梅克、乔恩·霍尔特、陈珊迪
在2026年亚太经合组织(APEC)会议(分会场IS02.1:人工智能与数字孪生重塑功率器件创新)上,我们的团队分享了两个已投入生产的AI/ML应用案例,这些案例源于我们与功率半导体制造商十余年的合作经验。本文总结了其中的关键经验。
这篇博客文章和演示文稿是该团队关于在半导体和功率半导体制造中部署人工智能/机器学习的实用方法系列出版物的一部分:
为什么功率半导体与众不同?
在逻辑和存储器制造领域,基于人工智能的良率提升已得到充分研究。但功率半导体(如碳化硅、氮化镓、IGBT、分立式硅器件)却面临着独特的挑战。 这些器件的材料组合更为复杂,缺陷率更高,且制造流程具有更强的垂直整合性:包括单晶棒生长、衬底分级、外延生长、多次老化测试、芯片粘接以及模块组装。相比之下,相关制造设施通常较为陈旧,在可追溯性和数据质量方面也相对不成熟——而成熟的硅晶圆厂早在多年前就已基本解决了这些问题。
在Yole发布的《2025年电力电子行业报告》中,有11家企业是Exensio的活跃用户,且均已使用该产品超过十年。我们在APEC上展示的两个应用案例,正是我们从这些部署中总结出的经验。
用例 1:碳化硅(SiC)中的衬底限制产量
问题
基板质量是导致碳化硅制造过程中良率下降的主要因素之一。问题在于:能否预测哪些基板会限制良率,并在投入昂贵的下游加工之前根据这一预测采取行动?
方法
识别致命缺陷的传统方法依赖于“致死率”指标:利用2×2混淆矩阵比较“无缺陷”和“有缺陷”芯片的良率。该方法基于每个缺陷类别的芯片级汇总数据。在硅片中,衬底几乎不含缺陷,因此主要关注的是在晶圆厂或代工厂生产过程中引入的在线缺陷。
在化合物半导体领域,情况则更为复杂。您需要在多个检测步骤、裸基板(外延前后)以及图案化晶圆(在线检测)之间进行工作。 晶粒级总结并不适用,因为未图案化基板上的晶粒网格尚未确定。此外,仅凭晶圆电气分选来判定晶粒良坏是不够的。功率器件需要在独特的负载条件下进行大电流、高电压测试,而这些条件通常在晶圆分选过程中无法实现。
我们的方法利用裸基板和外延缺陷数据来训练一个预测模型,该模型可生成预测的电气分级图,即在电气测试之前,针对每个芯片和每片晶圆对预期通过/失败结果进行的分类。该模型使操作员能够在将基板投入完整制造流程之前对其进行分级。此外,此类预测可针对任何虚拟芯片尺寸进行,并允许用户尝试不同的芯片尺寸以估算良率。
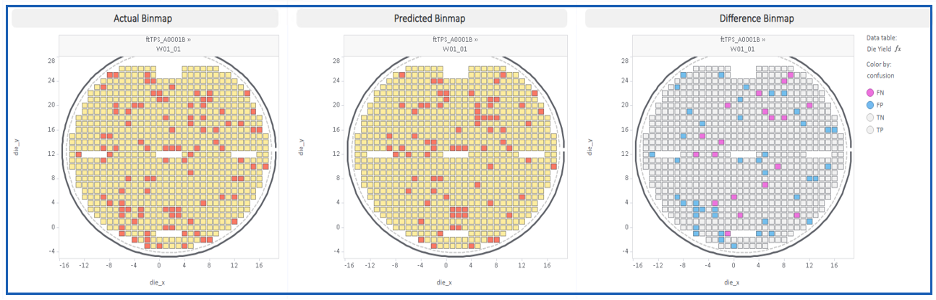
结果
下文讨论的结果基于我们对多家不同供应商提供的碳化硅衬底的实际经验。尽管如此,该方法同样适用于其他类型的半导体,并不局限于碳化硅。在实际生产中,该模型:
- 正确识别了与已发表的关于碳化硅缺陷消除机制的文献相符的限产底物
- 通过在上游阶段做出基材处置决策,可将产量提升几个百分点
- 生成实际值、预测值及差异的分箱图,使模型行为具有可解释性和可审计性
该模型还为每个缺陷类别提供了四个分类类别:
- TP(真阳性):实际通过,预测通过 — 判定正确
- TN(真阴性):实际未通过,预测未通过——判定正确
- FP(假阳性):实际失败,预测通过——检测不足,会导致良率下降
- FN(假阴性):实际通过,预测失败——过度设计,成本负担
生产挑战
从试点阶段过渡到正式生产阶段,暴露出了各种各样的挑战。
检测:同一基板可能在不同批次或物料流中使用不同的检测设备进行测量。不同设备之间的缺陷分类方案各不相同,未经标准化处理的缺陷计数无法直接进行比较。检测配方尚未成熟,且正在不断修订中。
空间对准:在裸基板上进行光学检测时采用全球晶圆坐标系。这些坐标必须与芯片坐标系正确对准。 许多老旧的晶圆厂在整体晶圆坐标系与芯片坐标系之间缺乏正确的配准。此外,非立方晶格半导体(如SiC)中的缺陷尺寸可能较大,且可能覆盖多个芯片。然而,检测扫描所获取的信息不足以了解这些缺陷的空间范围。
探针测试与老化测试:数据质量差是一个普遍存在的问题——方向错误、检测坐标与测试坐标之间的芯片偏移,以及不一致的芯片ID命名规则,使得空间对齐变得非同小可。因此,在构建有意义的模型之前,必须先进行数据清洗和验证。
模块 + 老化测试:许多制造商在实现芯片端到端的可追溯性方面面临困难。在基板层面进行优选和分级,意味着外延工艺后的晶圆厂批次可能与外延工艺前的批次构成截然不同。经过晶圆分选后,一个批次中的几乎每片晶圆都可能源自不同的外延前材料批次。在模块组装阶段,您需要对各个子组件中的单个芯片进行追踪。
缺失数据:会引入额外的偏差风险。如果你只是简单地剔除那些缺少检测数据的记录,那么这种剔除并非随机进行的。 你更有可能剔除特定工具类型、时间段或材料等级的记录,这会系统性地偏倚你的训练集。例如,缺失数据往往源于在组装过程中剔除不良芯片。剔除这些芯片意味着你移除了大量不良芯片,从而导致模型过于乐观(即“模型过强”)。
用例 2:面向组装的预测性芯片分级
问题
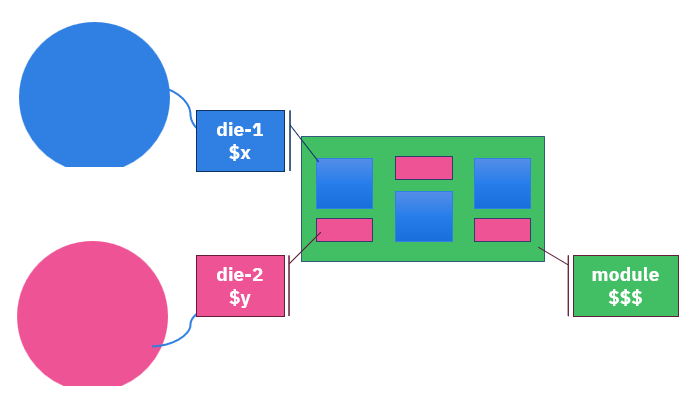
功率模块(例如汽车驱动逆变器)是成本极高的部件,由来自多个晶圆的多个芯片组装而成,这些芯片往往来自多种产品和多家供应商。一旦出现质量问题——即有缺陷的芯片被组装进模块中——造成的损失将非常巨大。问题在于:能否根据晶圆分选数据预测最终测试结果,并利用该预测结果在组装前优化芯片的布局?
这种情况并非功率半导体所独有。高端计算模块(用于数据中心的MCM)也面临同样的挑战。这两类产品每个模块都包含数十个芯片。在两种情况下,模块故障的成本都会波及到该模块中每个芯片的组装成本。
方法
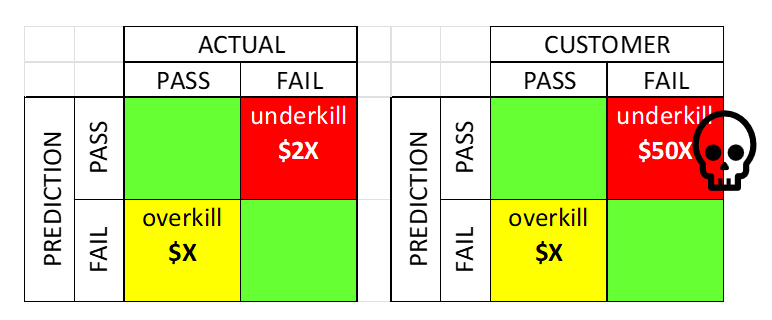
目标是构建一个基于晶圆分选参数数据训练的二分类器(用于判断模块最终测试的通过/失败),然后优化分类阈值,但优化目标不是准确率,而是最终模块成本。
为什么关注成本而非准确率?因为“检测不足”和“过度检测”的成本存在高度不对称性。将一个无法通过模块测试的芯片送入组装环节,会浪费整个模块的组装成本,这可能高达单个芯片成本的50倍。而对一个合格的芯片进行过度检测,仅会浪费该芯片本身的成本(x美元)。在这些不对称后果下,能够使总预期成本最小化的分类器才是最优的。
现实世界的复杂性
此类解决方案在实际部署中非常复杂:
- 数据混乱且存在缺失:生产中的实际分档图和参数图可能会出现空间失真、测试不完整,或因数据转换而损坏。这是因为测试机和探针台由不同的工程部门进行编程。探针台的任务是定位晶圆上的正确芯片,而测试机则专注于运行测试程序。 因此,测试机的输出结果往往会出现芯片尺寸、坐标甚至晶圆方向不正确的情况。
- 多重测试环节:晶圆探针测试、晶圆老化测试、模块组装测试、模块老化测试、最终测试,每个环节都有各自的数据格式、限值和分级规则。这引发了多个问题。良品与次品晶粒的“真实标准”是什么?对于那些测试合格但因空间异常筛选(例如GDBN)而被剔除、最终未能进入后续测试的晶粒,该如何处理?
- 包含数十个芯片的模块:不同的产品、不同的批次、不同的制造工艺,每种情况都需要独立的预测模型,并伴随各自的追溯要求。包含数十个芯片的模块会导致模型训练量呈指数级增长。训练此类模型需要强大的计算基础设施,而许多制造商难以承担。
- 多级子装配:零件需经过分级子装配流程,其中在某一步骤完成装配和测试的零件,将成为更高集成级别下一级子装配的起始物料。 这引出了一个问题——优化目标是什么?现在,每个子装配步骤都需要做出独立的决策(分类),但最终目标是所有子装配步骤的综合成本。随着子装配步骤数量的增加,复杂度会急剧上升。
- 可追溯性差:在功率半导体制造中,从晶圆到模块的芯片可追溯性需要专门的工程投入,并非自动完成
在生产部署过程中,我们不遗余力地确保所有制造环节的数据保持一致、追溯性得到保障,并在开始任何模型训练之前,确保数据集已具备分析条件。尽管如此,构建、验证、部署和维护此类模型仍然是一项挑战。
数据基础设施的紧迫性
这两个用例都指向同一个根本性挑战:让数据做好分析准备。据多位客户反馈,数据准备和验证工作占到成功将这些模型投入生产所需工程工作量的90%。
功率半导体行业的制造数据确实非常分散。对于无晶圆厂公司而言,芯片来自不同的供应商,随后送往不同的OSAT(封装测试服务商),将所有数据整合到一个平台上的工作变得异常艰巨。人们可能会认为,拥有自有制造能力的垂直整合器件制造商(IDM)会更轻松一些。 然而,事实远非如此。尽管数据归属于同一家公司,但它们分散在多个站点和多种系统中——包括MES、ERP、QMS、FDC和SPC系统;而且不同站点往往使用不同的系统。每个系统都成了信息孤岛,正因如此,在全企业范围内部署Exensio这类良率管理平台才显得至关重要。
以安森美半导体(onsemi)为例,说明此类部署的情况。在2025年12月的PDF Solutions用户大会上,安森美半导体的Tom Grein介绍了该公司如何将Exensio作为单一平台和全流程数据源,贯穿其整个碳化硅(SiC)制造流程:从碳化硅粉末到晶体生长、外延、器件制造,再到组件装配。 其数据溯源链涵盖:单晶生长 → 衬底 → 外延 → 晶圆 → 模块。这种端到端的数据基础设施绝非可有可无,而是任何严肃数据分析的必要前提。
行动号召:让您的数据做好迎接人工智能的准备
基于与功率半导体制造商十余年的生产部署经验,以下是构建成功AI战略基础所需的要素:
- 建立制造IT基础设施。如果数据无法以可用形式存在,就无法运行AI模型。因此,首要任务是投资建设数据采集、存储和访问基础设施。
- 打破数据孤岛。将所有制造数据、物料、在产晶圆、在产设备、组装及测试数据整合到单一平台中。无法关联的数据,就无法建模。
- 在源头对数据进行清理。理想情况下,应在数据采集环节就确保数据质量。如果无法做到这一点,则应建立一个企业级的“数据清理层”,在数据进入分析环境之前,对格式进行标准化处理、对数值进行验证,并对异常值进行标记。
- 在各站点和物料流中实现标准化。SEMI标准未能提供足够的标准化程度,无法应对数据分析带来的挑战。制造商需要针对每个数据领域制定自己的数据标准,并在各站点和物料流中一致地贯彻执行。
- 建立供应链可追溯性。功率半导体产品种类繁多,导致物料流向复杂多样。其物料流通常由全内制、部分外包和全外包(交钥匙)模式混合组成。从原材料到出货的模块,要追溯任何一颗芯片从出货模块到原始材料的来源绝非易事。然而,在功率半导体领域,正是这些材料往往决定了模块的优劣,以及它是否会从现场退回。
这五个步骤是实现卓越制造的先决条件。基于不完整、不一致或存在偏见的数据训练而成的AI模型会产生误导性的结果,而在生产处置系统中,误导性的结果会直接导致成本损失。
半导体行业的人工智能转型已全面展开。能够获得最大价值的制造商,未必是那些拥有最先进模型的企业,而是那些完成了将数据整理成可供学习形式这一幕后基础工作的企业。
本文基于2026年3月24日由PDF Solutions公司的Steve Zamek、Jon Holt和Sandy Chen在APEC 2026会议上发表的题为“利用高级分析与人工智能提升半导体成本与质量”(分会场IS02.1)的演讲。