
はじめに
半導体製造における機械学習の導入は、従来のアルゴリズムでは克服が困難な重大な障壁に直面している。業界では膨大なデータが生成される一方で、二つの根本的な課題が存在する:極端なクラス不均衡と、初期生産段階における訓練データセットの不足である。これらの問題は半導体テストにおいて特に深刻化する。テストでは不良率が0.5%を下回る場合があり、新製品では最小限の履歴データで即時的な品質予測が求められるためである。
リスクは甚大である。欠陥のあるダイが初期のウェーハ選別検査で検出されずに通過すると、高価な下流工程(パッケージング、アセンブリ、最終テスト)を経て最終的に故障する。これにより重大なコスト影響と時間的遅延が生じるが、より効果的な初期段階検出アルゴリズムによって防止可能である。同様に、良品ダイがウェーハ選別で不合格となる場合も、直接的なコスト影響と不要な廃棄物を招く。
最近の研究では、特殊な機械学習手法がこれらの制約に対処し、訓練データが極めて限られている場合でも有意義な性能向上を達成できることが実証されている。鍵となるのは、製造環境向けに特別に設計されたアルゴリズムを選択し、実世界の導入シナリオを反映した評価手法を実施することである。
クラス不均衡の課題を理解する
製造業データ不均衡の規模
半導体製造は、産業応用におけるクラス不均衡の最も極端な事例の一つである。高歩留まり生産環境では、故障率は頻繁に1%を下回り、一部の製品では0.5%という低い故障率を示す。ソフトビン分類による特定の故障モードを分析すると、不均衡はさらに顕著になる——初期データセットにおいて特定の故障タイプが全く存在しない場合もある。
この極端な偏りは、標準的な機械学習アルゴリズムに根本的な問題を引き起こす。従来のモデルは全体的な精度を最適化するため、全サンプルを単純に「合格」と予測する分類器でも、第II種誤り率を100%に保ちながら99%以上の精度を達成できる。このようなモデルは実際の欠陥を特定する上で実用的な価値を提供しない。
製造スケジュール上の制約
半導体データ収集の時間的特性は、クラス不均衡問題をさらに複雑化する。生産データは製造立ち上げ速度と生産量に応じて数か月かけて徐々に蓄積される。初期生産段階では、製造業者は品質判断を行うための予測モデルを必要とするが、従来の機械学習システムを訓練するのに十分な履歴データが存在しない。
これにより、研究者が「鶏と卵」問題と呼ぶ状況が生じる。製造業者は初期生産段階を最適化するために予測モデルを必要とするが、従来の機械学習手法では大規模でバランスの取れたデータセットが求められる。しかし、こうした重要な初期段階ではそのようなデータセットが存在しないのである。
製造環境向け専用アルゴリズム
アルゴリズム選択基準
59の生産ロット(各ロット25枚のウェーハを含む)を対象に実施された研究では、ダイあたり約17,500のテストパラメータを用いて、3つの異なるアルゴリズム的アプローチを評価した。選定基準は、製造環境に適した計算効率を維持しつつ、クラス不均衡に対処可能なアルゴリズムに焦点を当てた。
評価フレームワークでは二つの手法を採用した:実世界のモデル再学習シナリオをシミュレートする時間的検証と、ベースライン性能評価のための従来の5分割交差検証である。この二重アプローチにより、実用的な適用性と方法論的な厳密性の両方が保証される。
現職分類者の特性
ベースラインアルゴリズムは、ブースティング技術を通じて大規模データセット、欠損値、外れ値の効率的な処理を実現した。この手法はバイアスを低減し、増分学習をサポートする——データが継続的に蓄積される製造環境において極めて重要である。ただし、ブースティングアルゴリズムは小規模データセットでは過学習の影響を受けやすく、学習中に膨大な計算リソースを必要とする。
主な性能特性は以下の通りです:
- スケーリングのための分散コンピューティング能力
- 継続的データ統合のための増分学習サポート
- 欠損値と外れ値の堅牢な処理
- より高い計算トレーニングコスト
高度なサンプリングベース分類器
特化アルゴリズム(分類器A)は、その中核アーキテクチャにおいて多数クラスに対するランダムアンダサンプリングと少数クラスに対するオーバーサンプリングを統合する。この手法は、半導体テストデータに特徴的な極端なクラス不均衡を特に解決すると同時に、外れ値に対する頑健性を維持する。
性能上の利点には以下が含まれます:
- 自動サンプリングによる学習データの内部再バランス調整
- ランダム化特徴量選択による分散低減
- 正則化による組み込み型外れ値頑健性
- 手動によるハイパーパラメータ調整の必要性が低減
このアルゴリズムは分散低減に焦点を当て、アンサンブル手法を通じてモデル全体の精度を向上させるため、製造初期段階で一般的な小規模データセットのシナリオに特に適している。
伝統的地域情報分類器
従来の機械学習手法(分類器B)は、予測判断にデータ点周辺の局所情報を活用する。高速な学習時間と漸進的学習能力を提供する一方で、これらの手法は高次元データへの対応に苦戦し、ノイズや外れ値に対する感受性を示す。これは製造環境において重大な制約となる。
パフォーマンス分析と結果
AUC-ROC性能比較
時系列検証条件下において、データセットが限られたシナリオを模擬した場合、特化したサンプリングベース分類器は一貫して優れた性能を達成した。最初の10ロットで訓練された場合、このアルゴリズムは既存分類器と比較して、AUC-ROCスコアの中央値において約2パーセントポイントの改善を示した。
具体的なパフォーマンス指標:
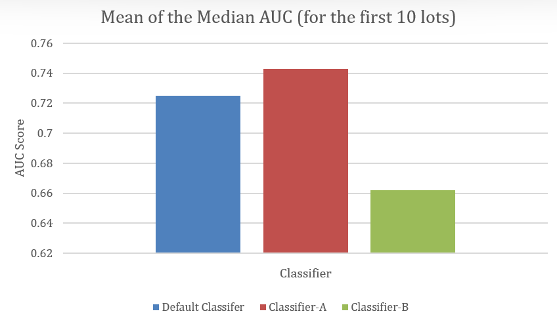
性能上の優位性は、初期の学習段階でより顕著になる。この段階では、専用アルゴリズムの不均衡データ処理能力が最大の効果を発揮する。追加の学習データが利用可能になるにつれ、性能差は縮小するが、一貫して有利な状態を維持する。
計算効率のトレードオフ
実行時分析により、学習速度と推論性能の間に重要なトレードオフが明らかになった。従来の局所情報分類器は最速の学習時間を示したが、推論速度は最も遅かった。二大候補の間では、既存の分類器が推論速度でわずかな優位性を示した一方、特化型分類器は推論処理に約3倍の時間を要した。
ただし、専門的な分類器によって得られる2パーセントポイントのAUC向上は、特に製造環境における不良ダイスの誤分類がコスト面で及ぼす影響を考慮すると、追加の計算オーバーヘッドを正当化するものである。
統計的有意性と変動性
時間的検証アプローチでは、性能変動を定量化するため、異なる乱数シードを用いた複数回の実験反復を実施した。結果から、専用分類器は様々なデータ分割や初期化条件において一貫した性能優位性を示し、これはデータセット固有のアーティファクトではなく、堅牢なアルゴリズム的改善であることを示唆している。
製造環境における実装上の考慮事項
特徴量エンジニアリングと特徴量選択
半導体テストデータの高次元性(ダイあたり約17,500のパラメータ)は、堅牢な特徴量スクリーニングパイプラインを必要とする。効果的な実装には、予測信号の強い特徴量を特定すると同時に、計算上の複雑性を管理し、データ量が限られる状況での過学習を回避することが求められる。
パラメータのスクリーニングは、モデルの複雑さと利用可能な訓練データのバランスを取る際に特に重要となる。専用アルゴリズムは内部の特徴選択メカニズムを通じて高次元特徴空間を処理する能力を示し、手動による特徴量設計の負担を軽減した。
ハイパーパラメータ最適化
従来の手法のように膨大な手動によるハイパーパラメータ調整を必要とせず、専用分類器は組み込みの分散制御と自動サンプリング戦略を備えています。これによりデプロイの複雑さが軽減され、製造環境におけるモデルの迅速な実装が可能となります。
アルゴリズムの正則化メカニズムは、過学習に対する固有の保護機能を提供しつつ、少数クラスパターンに対する感度を維持する。これは半導体欠陥検出アプリケーションにおいて極めて重要なバランスである。
既存インフラとの統合
現代の製造環境では、既存のデータ処理システムや意思決定システムとのシームレスな統合が求められます。専用アルゴリズムは増分学習をサポートし、生産データの蓄積に伴いモデルを継続的に改善できるため、モデル全体の再学習を必要としません。
この能力は製造の運用スケジュールに整合し、生産が初期立ち上げからフルボリューム生産へ拡大する過程において、持続可能なモデル保守アプローチを提供する。
事業への影響とコストへの影響
早期欠陥検出の価値
主なビジネス価値は、初期段階における欠陥検出能力の向上に由来する。最終テストではなくウェーハ選別段階で潜在的な故障を特定することで、メーカーは故障の可能性が高いダイのダウンストリーム処理コストを回避できる。パッケージング、組立、最終テスト工程に伴う多大な費用を考慮すると、初期検出精度のわずかな向上でも大幅なコスト削減につながる。
より速い投資回収
クラス不均衡に対処する専用アルゴリズムを導入する製造業者は、十分なバランスの取れた訓練データを蓄積するために数か月待つ必要がなく、稼働初日から予測モデルを実現します。これにより、意思決定支援が即座に可能となり、AI/ML投資イニシアチブの投資回収が加速されます。
下流工程における廃棄物の削減
ウェハー選別から最終テストまでの予測精度向上は、不良ダイが高価な製造工程へ進むのを防ぐことで、直接的に下流工程の廃棄物を削減します。専門的な分類装置は、困難なサンプルを専門的に識別することで、第一種誤り率と第二種誤り率の両方を低減し、大きな価値を提供します。
将来の検討事項と拡張性
データ成長とモデル進化
製造量が増加し追加データが入手可能になるにつれ、専用アルゴリズムの漸進的学習能力により、完全な再学習なしにモデルの継続的な改善が可能となる。この手法は初期段階の学習上の利点を維持しつつ、費用対効果の高いモデル保守を実現する。
アンサンブル手法
個々のアルゴリズムは明らかな性能上の優位性を示しているが、今後の研究では複数の特化型分類器を組み合わせたアンサンブル手法の検討が考えられる。ただし、現時点の結果から、特化型サンプリングベース分類器は既に内部的にアンサンブル技術を組み込んでいるため、外部からのアンサンブル戦略による追加的な性能向上は限定的となる可能性がある。
製造業におけるAI導入の最適化
半導体産業特有の制約——時間的データ収集パターン、極端なクラス不均衡、即時的なモデル要求——は、従来のアルゴリズムを超えた専門的な機械学習アプローチを必要とする。研究によれば、慎重に選択されたアルゴリズムは、訓練データセットが著しく制限されている場合でも、有意義な性能向上を達成できることが実証されている。
専門的なクラス不均衡アルゴリズムによって達成された2パーセントポイントのAUC改善は、製造コストの削減、品質管理の向上、AI投資の回収期間短縮に直結する。業界がAI導入を拡大し続ける中、これらの専門的なアプローチは製造環境に内在する根本的なデータ制約を克服するための実用的な解決策を提供する。
成功には、標準的な機械学習の実践を超えて、製造上の制約に特化して設計されたアルゴリズムへの移行が不可欠である。半導体テスト用途において、特殊なクラス不均衡技術を採用することの有効性は明確に実証されており、生産データの蓄積に伴い継続的改善の基盤を構築しつつ、即時のビジネス価値を提供する。