
引言
在半导体制造领域,机器学习的应用面临着传统算法难以克服的关键障碍。尽管该行业产生海量数据,但两大根本性挑战始终存在:极端类不平衡问题,以及初期生产阶段训练数据集的匮乏。这些问题在半导体测试环节尤为突出——此时故障率可能降至0.5%以下,而新产品需要在历史数据极少的情况下立即进行质量预测。
风险不容小觑。当缺陷晶粒在早期晶圆分选测试中未被发现便通过时,它们将进入昂贵的下游工序——封装、组装及最终测试——最终导致产品失效。这将造成巨大的成本损失和时间延误,而更有效的早期检测算法本可避免这些问题。同样地,当良品晶粒在晶圆分选中被误判为缺陷时,也会直接导致成本损失和不必要的浪费。
最新研究表明,专门的机器学习方法能够突破这些限制,即使在训练数据严重不足的情况下,也能实现显著的性能提升。关键在于选择专为制造环境设计的算法,并采用能反映实际部署场景的评估方法。
理解班级失衡的挑战
制造业数据失衡的规模
半导体制造是工业应用中类不平衡现象最极端的实例之一。在高良率的生产环境中,失效率常低于1%,部分产品的失效率甚至低至0.5%。当通过软分类法分析特定失效模式时,这种不平衡现象更为显著——某些失效类型在初始数据集中可能完全缺失。
这种极端偏斜性给标准机器学习算法带来了根本性问题。传统模型追求整体准确率优化,这意味着一个简单地将所有样本预测为"合格"的分类器,在保持100%的第二类错误率(即漏检率)的同时,仍能达到99%以上的准确率。此类模型对识别实际缺陷毫无实际价值。
制造时间线约束
半导体数据采集的时序特性加剧了类别失衡问题。生产数据需随制造爬坡率和产量变化,历经数月逐步累积。在初期生产阶段,制造商虽需预测模型来制定质量决策,但现有历史数据不足以训练传统机器学习系统。
这形成了研究人员所称的“先有鸡还是先有蛋”的困境:制造商需要预测模型来优化早期生产阶段,但传统机器学习方法却要求使用庞大且平衡的数据集——而这些关键的早期阶段恰恰缺乏这样的数据集。
面向制造环境的专用算法
算法选择标准
针对59个生产批次(每批含25片晶圆)开展的研究,每个晶粒约有17,500个测试参数,评估了三种不同的算法方案。选择标准侧重于能够处理类不平衡问题,同时保持适合制造环境的计算效率的算法。
该评估框架采用了两种方法:模拟真实世界模型重训场景的时间验证,以及用于基线性能评估的传统五折交叉验证。这种双重方法确保了实践适用性与方法论严谨性的兼顾。
现任分类器特征
基线算法通过提升技术,有效处理了大规模数据集、缺失值和异常值。该方法可降低偏差并支持增量学习——这对数据持续累积的制造环境至关重要。然而,提升算法在较小数据集上易出现过拟合,且训练过程中需要大量计算资源。
关键性能特征包括:
- 分布式计算能力用于扩展
- 增量学习支持持续数据集成
- 对缺失值和异常值的稳健处理
- 更高的计算训练成本
基于采样的先进分类器
该专用算法(分类器A)在其核心架构中整合了多数类别的随机欠采样与少数类别的过采样技术。该方法专门针对半导体测试数据中典型的极端类别失衡特征,同时保持对异常值的鲁棒性。
性能优势包括:
- 通过自动采样实现训练数据的内部再平衡
- 通过随机特征选择实现方差缩减
- 通过正则化实现内置异常值鲁棒性
- 减少手动超参数调优需求
该算法通过集成技术聚焦于方差缩减以提升整体模型精度,使其特别适用于制造初期常见的小型数据集场景。
传统本地信息分类器
经典机器学习方法(分类器-B)利用数据点周围的局部信息进行预测决策。尽管这些方法具备快速训练和增量学习能力,但在处理高维数据时表现吃力,且对噪声和异常值敏感——这些特性在制造环境中构成显著限制。
性能分析与结果
AUC-ROC性能比较
在模拟有限数据集场景的时间验证条件下,基于采样的专用分类器始终表现出更优性能。当使用前10个批次进行训练时,该算法的中位数AUC-ROC评分较现有分类器提升约2个百分点。
具体绩效指标:
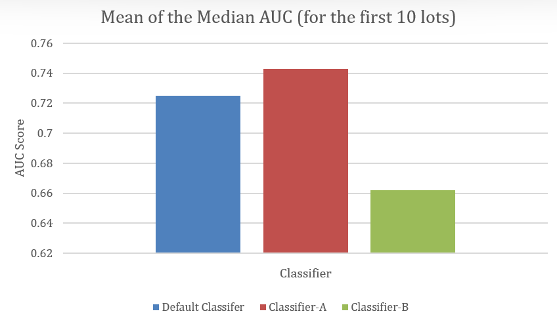
在早期训练阶段,性能优势更为显著,此时专用算法的类不平衡处理能力能发挥最大效益。随着更多训练数据的加入,性能差距逐渐缩小,但优势始终保持稳定。
计算效率权衡
运行时分析揭示了训练速度与推理性能之间的重要权衡关系。传统局部信息分类器展现出最快的训练速度,但推理速度最慢。在两大主要竞争者中,现行分类器在推理速度上略占优势,而专用分类器则需要约三倍的时间完成推理操作。
然而,专用分类器带来的2%AUC提升足以证明额外计算开销的合理性,尤其考虑到在制造环境中误判缺陷晶圆所带来的成本影响。
统计学意义与变异性
时间验证方法包含多次实验重复,采用不同随机种子以量化性能波动。结果表明,该专用分类器在不同数据划分和初始化条件下均展现出稳定的性能优势,这表明其实现了稳健的算法改进,而非特定数据集的伪像。
制造环境的实施注意事项
特征工程与特征选择
半导体测试数据的高维特性——每颗芯片约含17,500个参数——要求构建稳健的特征筛选流程。有效实施需在有限数据场景下,既识别出具有强预测信号的特征,又需控制计算复杂度并避免过拟合。
在权衡模型复杂度与可用训练数据时,参数筛选显得尤为关键。这些专用算法通过内部特征选择机制,展现出处理高维特征空间的能力,从而减轻了人工特征工程的负担。
超参数优化
与需要大量手动超参数调优的传统方法不同,该专用分类器集成了内置方差控制和自动化采样策略。这降低了部署复杂性,使模型能在制造环境中更快地实现。
该算法的正则化机制在保持对少数类模式敏感性的同时,提供了内在的过拟合防护能力——这对半导体缺陷检测应用而言是至关重要的平衡点。
与现有基础设施的集成
现代制造环境需要与现有数据处理和决策系统实现无缝集成。专用算法支持增量学习,能够在生产数据不断积累的过程中持续优化模型,而无需进行完整的模型重新训练。
该能力与制造运营时间框架相契合,并为生产从初期爬坡到全面量产的规模扩展阶段提供了可持续的模型维护方案。
业务影响与成本影响
早期缺陷检测价值
主要商业价值源于早期缺陷检测能力的提升。通过在晶圆分选阶段而非最终测试阶段识别潜在故障,制造商可避免对可能失效的芯片进行后续加工处理。鉴于封装、组装及最终测试环节涉及的巨额成本,即使早期检测准确率仅有小幅提升,也能带来显著的成本节约。
更快的投资回报
采用专门算法解决类别不平衡问题的制造商,能够从生产首日即获得预测模型,而非耗时数月积累足够的平衡训练数据。这使得决策支持得以即时实现,并加速人工智能/机器学习投资项目的回报周期。
减少下游废弃物
改进的晶圆分选至最终测试预测精度,通过阻止缺陷芯片进入昂贵的制造工序,直接减少了下游浪费。专业分选设备凭借其精准识别复杂样本的能力,显著降低了第一类和第二类错误率,从而创造了巨大价值。
未来考量与可扩展性
数据增长与模型演进
随着生产量的增加和更多数据的获取,专用算法的增量学习能力能够在无需完全重新训练的情况下实现模型的持续改进。这种方法在保持早期学习优势的同时,提供了经济高效的模型维护方案。
集成方法
尽管单个算法展现出明显的性能优势,未来研究可探索整合多种专用分类器的集成方法。但现有结果表明,基于采样的专用分类器内部已融合了集成技术,这可能限制外部集成策略带来的额外收益。
优化制造业中的人工智能实施
半导体行业的独特制约因素——时间序列数据采集模式、极端类不平衡问题以及即时模型需求——要求采用超越传统算法的专用机器学习方法。研究表明,即使在训练数据集严重受限的情况下,精心选择的算法仍能实现显著的性能提升。
专业化的数据失衡算法实现了2%的AUC提升,这直接转化为生产成本降低、质量控制优化以及人工智能投资回报加速。随着行业持续扩大人工智能应用规模,这些专业化方法为克服制造环境中固有的基础数据限制提供了切实可行的解决方案。
成功需要超越标准机器学习实践,转向专门针对制造约束设计的算法。现有证据明确支持在半导体测试应用中采用专门的类不平衡技术,这既能立即创造商业价值,又能随着生产数据的积累为持续改进奠定基础。