
 化合物半导体行业面临着一个持续的挑战:晶体生长和外延过程中引入的缺陷往往要到最终测试或组装时才会显现,此时再采取措施防止良率损失已为时过晚且代价高昂。 对于使用碳化硅(SiC)、氮化镓(GaN)和砷化镓(GaAs)材料的制造商而言,问题已不再是衬底缺陷是否会影响良率,而是如何在晶圆进入下游工序前预测并减轻这种影响。
化合物半导体行业面临着一个持续的挑战:晶体生长和外延过程中引入的缺陷往往要到最终测试或组装时才会显现,此时再采取措施防止良率损失已为时过晚且代价高昂。 对于使用碳化硅(SiC)、氮化镓(GaN)和砷化镓(GaAs)材料的制造商而言,问题已不再是衬底缺陷是否会影响良率,而是如何在晶圆进入下游工序前预测并减轻这种影响。
化合物半导体制造挑战
化合物半导体已成为硅材料无法满足的应用领域不可或缺的存在。其卓越的电子迁移率为驱动现代通信的5G/6G射频芯片和高速电子设备提供了保障;直接带隙特性使LED、激光二极管和红外传感器能够高效发光;高击穿电压与优异的导热性能相结合,使其能在电动汽车电力电子设备、快速充电器和可再生能源系统所需的极端条件下稳定运行。
然而,这些性能优势伴随着制造复杂性,从而引发三个关键问题:
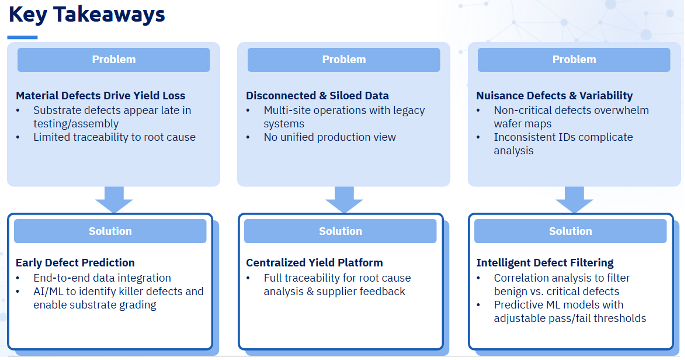
源头材料缺陷。 晶体生长与外延生长是成本高昂的工艺环节,缺陷往往在此阶段产生,但这些缺陷通常要到后期测试和组装阶段才会显现。此时,晶圆已增值显著,最终却可能报废或导致良率低下。若缺乏集成数据系统,追溯这些缺陷在衬底或外延层的起源将极为困难。
孤岛化的数据分散在不同的系统中。 制造数据分散在多个站点、工厂和设备系统中。若缺乏将基板缺陷、在线工艺数据和最终电气测试结果关联起来的集中视图,根本原因分析就只能成为耗时的手工操作,而非系统化的工程流程。
干扰缺陷淹没了关键信号。 晶圆缺陷图充斥着不影响良率的非关键性"干扰缺陷",掩盖了真正致命的缺陷。再加上数据质量问题——例如返工导致的基板ID变更和批次拆分——使得噪声与信号的比率难以进行有效分析。
端到端数据集成方法
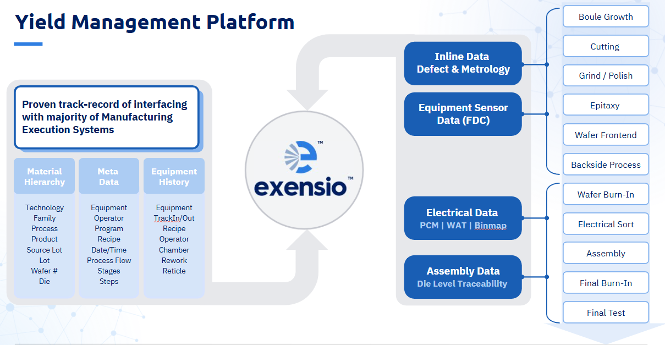
要应对这些挑战,需要一个能够整合整个制造流程数据的平台——从晶棒生长、外延生长、晶圆前端加工,直至最终的封装和测试。Exensio平台将在线缺陷与计量数据、设备传感器数据、电气测试结果以及封装可追溯性整合为单一连贯的层级体系。
这种统一的数据结构能够追溯到失败晶片的原材料批次、使用的具体工具和配方,甚至追溯到生产该晶片的工艺条件。对于化合物半导体制造商而言,这种完整的可追溯性是使预测性机器学习成为现实的基础。
该平台目前已在全球超过100家半导体企业部署,其中逾10家化合物半导体制造商将其用于集成设备制造商、代工厂及无晶圆厂模式下的全企业级良率管理。
机器学习方法:从基板缺陷到良率预测
核心创新在于将基板缺陷——即制造流程初期出现的缺陷——与最终电气测试的合格/不合格结果建立关联。这使得我们能够识别真正影响良率的缺陷类型,在更早阶段预测良率,甚至在基板进入下游工序前对其进行分级。
分析流程
机器学习工作流包含五个关键步骤:
- 数据采集与映射。 基底缺陷数据(或后期工艺步骤的在线缺陷数据)与电气测试binmap数据同步采集。Python脚本将绝对缺陷坐标映射至binmap配置定义的晶粒坐标系,实现缺陷计数与电气测试结果的晶粒级直接比对。
- 智能缺陷过滤。 并非所有缺陷都具有同等重要性。该Python脚本专门识别并过滤两类特殊缺陷:
- 强效杀伤剂:缺陷的杀伤率大于0.9,几乎总会导致芯片失效。含有强杀伤缺陷的芯片将自动标记为失败。
- 负相关缺陷:指在合格模具中异常频繁出现的缺陷,而非在不合格模具中,这表明它们并非限制产量的关键因素。
这两个类别均从训练数据集中移除,因此模型仅专注于有意义的预测信号。
- 特征降维。 缺陷特征经过标准化处理,并应用主成分分析法(PCA),保留95%的方差。这种降维方法既能捕捉关键信息,又可避免模型因冗余或低效特征而过载。
- 模型训练。 基于过滤后精简的特征集,采用10折交叉验证(平衡各类别分布以避免单一结果偏差)训练XGBoost分类器。该模型通过学习缺陷特征,可预测单个芯片的合格/不合格概率。
- 预测与评估。 训练后的模型可预测每个晶粒是否通过电气测试。覆盖规则确保存在严重致命缺陷的晶粒无论模型概率输出如何均自动判定为不合格。结果包含混淆矩阵、分类指标(精确率、召回率、F1分数),以及最关键的预测与实际晶圆良率对比分析。
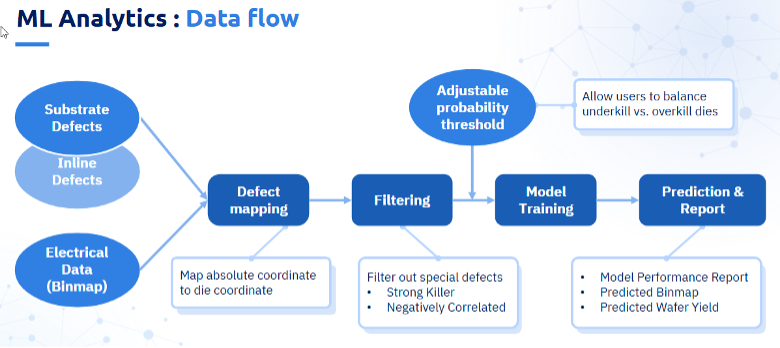
平衡“杀伤不足”与“杀伤过度”
关键特性在于可调节的概率阈值,用户可据此根据业务优先级调整模型行为。较低阈值会增加漏检风险(导致不良晶圆漏检),但可能降低误检率(减少良品报废)。较高阈值则产生相反效果。这种灵活性使工程师能够根据具体经济约束条件,在良率损失与制造成本之间取得平衡。
用于生产环境的交互式用户界面
分析工具只有在工程师能够实际应用于日常工作中才具有价值。该方案包含一个交互式用户界面,旨在实现直观导航:
- A 登陆页面 提供概览和侧边栏导航
- 一个 介绍页面 列出了输入要求和数据导入流程
- A 使用说明页面 引导用户完成输入设置,并演示如何用自定义Python脚本替换默认模型
- 预测 预测页面 是实际操作的核心区域,包含用于选择分组列、执行缺陷坐标映射、设置通过/失败阈值以及执行预测的输入字段。
- 结果部分 显示特殊缺陷类别、分类性能指标、三向晶圆图比较(实际图、预测图及显示假阴性与假阳性的差异图),以及按晶圆和批次划分的实际与预测良率表格/散点图
- 一个 附录页 汇总了支持该模板的背景知识
关键的是,用户可以在模板内直接打开并修改Python脚本,从而根据自身的工艺知识和需求对模型进行调整。
实际应用:碳化硅案例研究
该方法已在碳化硅上得到验证——这种宽带隙材料对电动汽车和高功率应用至关重要。在此案例研究中,基底缺陷被映射至电气测试结果,缺陷经过过滤与分类,并训练XGBoost模型以预测芯片级良率。
结果表明具有以下实用功能:
- 基于衬底缺陷的早期良率预测 基于基底缺陷的早期预测(在显著增值前)
- 致命缺陷类型的识别 真正影响良率的缺陷与良性干扰缺陷的区分
- 基板分级 晶圆进入昂贵下游工艺前的分级潜力
- 可视化证据 通过二进制映射比较,工程师可据此指导决策
- 定量指标 用于模型性能和产量预测准确性
解决核心制造挑战
这种集成方法直接解决了化合物半导体制造中的三大根本性挑战:
材料缺陷延迟显现: 通过采用端到端数据集成与机器学习技术,制造商能够在流程更早阶段预测缺陷影响,识别关键缺陷,并在晶圆进入下游工序前实现基板分级。
孤立的、分散的数据: 该平台将来自多个站点和旧系统的数据整合到单一环境中,为根本原因分析提供完整的可追溯性,并实现更有效的供应商反馈。
干扰缺陷与变异性: 智能缺陷过滤与相关性分析可区分良性缺陷与真正关键缺陷,而具备可调阈值的预测性机器学习模型,能让用户根据自身风险与成本优先级,在漏检与漏报之间实现平衡。
前进之路
随着化合物半导体在5G/6G通信、电动汽车及可再生能源等下一代应用中日益关键,制造商亟需能够应对日益复杂需求的工具。通过整合统一数据集成、智能筛选与机器学习预测技术,可实现更早干预、更明智决策,最终提升良品率。
Exensio平台已获得超过10家化合物半导体制造商的验证,并被应用于实际生产中。随着行业规模持续扩大,预测并预防源缺陷导致的良率损失的能力,将不仅是竞争优势,更将成为制造企业保持竞争力的必要条件。