
Introduction
Machine learning adoption in semiconductor manufacturing faces critical obstacles that traditional algorithms struggle to overcome. While the industry generates massive amounts of data, two fundamental challenges persist: extreme class imbalance and limited training datasets during initial production phases. These issues become particularly acute in semiconductor testing, where failure rates can drop below 0.5% and new products require immediate quality predictions with minimal historical data.
The stakes are substantial. When defective dies pass through early wafer sort testing undetected, they proceed through expensive downstream processes—packaging, assembly, and final testing—before ultimately failing. This creates significant cost implications and time delays that could be prevented through more effective early-stage detection algorithms. Similarly, when a good die fails the wafer sort, it also directly leads to cost implications and unnecessary waste.
Recent research demonstrates that specialized machine learning approaches can address these constraints, achieving meaningful performance improvements even with severely limited training data. The key lies in selecting algorithms specifically designed for manufacturing environments and implementing evaluation methodologies that reflect real-world deployment scenarios.
Understanding the Class Imbalance Challenge
The Scale of Manufacturing Data Imbalance
Semiconductor manufacturing presents one of the most extreme examples of class imbalance in industrial applications. In high-yield production environments, failure rates frequently fall below 1%, with some products experiencing failure rates as low as 0.5%. When analyzing specific failure modes through soft bin classifications, the imbalance becomes even more pronounced—certain failure types may have zero representation in initial datasets.
This extreme skew creates fundamental problems for standard machine learning algorithms. Traditional models optimize for overall accuracy, which means a classifier that simply predicts “pass” for all samples can achieve 99%+ accuracy while maintaining 100% Type II error rates. Such models provide no practical value for identifying actual defects.
Manufacturing Timeline Constraints
The temporal nature of semiconductor data collection compounds the class imbalance problem. Production data accumulates gradually over months, depending on manufacturing ramp rates and production volumes. During initial production phases, manufacturers need predictive models to make quality decisions, yet insufficient historical data exists to train conventional machine learning systems.
This creates what researchers term a “chicken and egg” problem: manufacturers require predictive models to optimize early production phases, but traditional machine learning approaches demand large, balanced datasets that don’t exist during these critical early stages.
Specialized Algorithms for Manufacturing Environments
Algorithm Selection Criteria
Research conducted on 59 production lots containing 25 wafers each, with approximately 17,500 test parameters per die, evaluated three distinct algorithmic approaches. The selection criteria focused on algorithms capable of handling class imbalance while maintaining computational efficiency suitable for manufacturing environments.
The evaluation framework employed two methodologies: temporal validation simulating real-world model retraining scenarios, and traditional 5-fold cross-validation for baseline performance assessment. This dual approach ensures both practical applicability and methodological rigor.
Incumbent Classifier Characteristics
The baseline algorithm demonstrated efficient handling of large datasets, missing values, and outliers through boosting techniques. This approach reduces bias and supports incremental learning—critical for manufacturing environments where data continuously accumulates. However, boosting algorithms can be susceptible to overfitting on smaller datasets and require significant computational resources during training.
Key performance characteristics include:
- Distributed computing capability for scaling
- Incremental learning support for continuous data integration
- Robust handling of missing values and outliers
- Higher computational training costs
Advanced Sampling-Based Classifier
The specialized algorithm (Classifier-A) integrates random under-sampling of majority classes and over-sampling of minority classes within its core architecture. This approach specifically addresses the extreme class imbalance characteristic of semiconductor testing data while maintaining robustness to outliers.
Performance advantages include:
- Internal rebalancing of training data through automated sampling
- Variance reduction through randomized feature selection
- Built-in outlier robustness via regularization
- Reduced manual hyperparameter tuning requirements
The algorithm focuses on variance reduction to improve overall model accuracy through ensemble techniques, making it particularly suitable for small dataset scenarios common in early manufacturing phases.
Traditional Local Information Classifier
Classical machine learning approaches (Classifier-B) utilize local information around data points for prediction decisions. While offering fast training times and incremental learning capabilities, these methods struggle with high-dimensional data and demonstrate sensitivity to noise and outliers—significant limitations in manufacturing environments.
Performance Analysis and Results
AUC-ROC Performance Comparison
Under temporal validation conditions simulating limited dataset scenarios, the specialized sampling-based classifier achieved consistently superior performance. When trained on the first 10 lots, the algorithm demonstrated approximately 2 percentage points improvement in median AUC-ROC scores compared to the incumbent classifier.
Specific Performance Metrics:
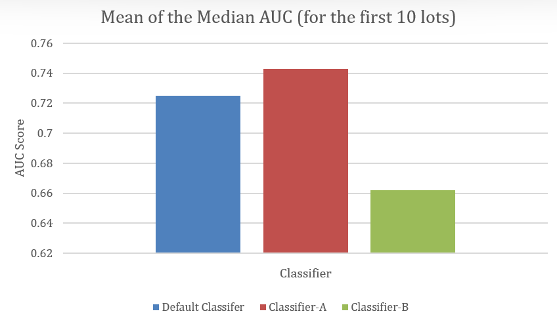
The performance advantage becomes more pronounced in early training phases, where the specialized algorithm’s class imbalance handling capabilities provide maximum benefit. As additional training data becomes available, the performance gap narrows but remains consistently favorable.
Computational Efficiency Trade-offs
Runtime analysis revealed important trade-offs between training speed and inference performance. The traditional local information classifier demonstrated fastest training times but slowest inference speeds. Between the two primary contenders, the incumbent classifier showed marginal advantages in inference speed, while the specialized classifier required approximately three times longer for inference operations.
However, the 2 percentage-point AUC improvement provided by the specialized classifier justifies the additional computational overhead, particularly given the cost implications of misclassified defective dies in manufacturing environments.
Statistical Significance and Variability
The temporal validation approach included multiple experimental repetitions with different random seeds to quantify performance variability. Results demonstrated consistent performance advantages for the specialized classifier across different data splits and initialization conditions, indicating robust algorithmic improvements rather than dataset-specific artifacts.
Implementation Considerations for Manufacturing Environments
Feature Engineering and Selection
The high-dimensional nature of semiconductor test data—approximately 17,500 parameters per die—necessitates robust feature screening pipelines. Effective implementation requires identifying features with strong predictive signal while managing computational complexity and avoiding overfitting in limited data scenarios.
Parameter screening becomes particularly critical when balancing model complexity against available training data. The specialized algorithms demonstrated ability to handle high-dimensional feature spaces through internal feature selection mechanisms, reducing the burden of manual feature engineering.
Hyperparameter Optimization
Unlike traditional approaches requiring extensive manual hyperparameter tuning, the specialized classifier incorporates built-in variance control and automated sampling strategies. This reduces deployment complexity and enables faster model implementation in manufacturing environments.
The algorithm’s regularization mechanisms provide inherent protection against overfitting while maintaining sensitivity to minority class patterns—a critical balance for semiconductor defect detection applications.
Integration with Existing Infrastructure
Modern manufacturing environments require seamless integration with existing data processing and decision-making systems. The specialized algorithms support incremental learning, enabling continuous model improvement as production data accumulates without requiring complete model retraining.
This capability aligns with manufacturing operational timeframes and provides sustainable model maintenance approaches as production scales from initial ramp to full volume manufacturing.
Business Impact and Cost Implications
Early Defect Detection Value
The primary business value derives from improved early-stage defect detection capability. By identifying potential failures at wafer sort rather than final test, manufacturers avoid downstream processing costs for dies likely to fail. Given the significant expenses associated with packaging, assembly, and final testing operations, even modest improvements in early detection accuracy generate substantial cost savings.
Faster Return on Investment
Manufacturers implementing specialized algorithms addressing class imbalance achieve predictive models from production day one, rather than waiting months to accumulate sufficient balanced training data. This enables immediate decision-making support and faster return on AI/ML investment initiatives.
Reduced Downstream Waste
Improved wafer sort to final test prediction accuracy directly reduces downstream waste by preventing defective dies from proceeding through expensive manufacturing steps. The specialized classifier offers substantial value by expertly identifying challenging samples, thereby reducing both Type I and Type II error rates..
Future Considerations and Scalability
Data Growth and Model Evolution
As manufacturing volumes increase and additional data becomes available, the specialized algorithms’ incremental learning capabilities enable continuous model improvement without complete retraining. This approach provides cost-effective model maintenance while preserving early-stage learning advantages.
Ensemble Approaches
While individual algorithms demonstrate clear performance advantages, future research may explore ensemble approaches combining multiple specialized classifiers. However, current results indicate that the specialized sampling-based classifier already incorporates ensemble techniques internally, potentially limiting additional gains from external ensemble strategies.
Optimizing AI Implementation in Manufacturing
The semiconductor industry’s unique constraints—temporal data collection patterns, extreme class imbalance, and immediate model requirements—demand specialized machine learning approaches beyond traditional algorithms. Research demonstrates that carefully selected algorithms can achieve meaningful performance improvements even with severely limited training datasets.
The 2 percentage-point AUC improvement achieved by specialized class imbalance algorithms translates directly to reduced manufacturing costs, improved quality control, and faster return on AI investment. As the industry continues scaling AI adoption, these specialized approaches provide practical solutions for overcoming fundamental data limitations inherent in manufacturing environments.
Success requires moving beyond standard machine learning practices toward algorithms specifically engineered for manufacturing constraints. The evidence clearly supports adopting specialized class imbalance techniques for semiconductor testing applications, providing immediate business value while establishing foundations for continuous improvement as production data accumulates.